本文收录了常用的字符串算法:进制Hash,Trie树,KMP,Manacher,AC自动机。至于后缀数组和后缀自动机(SA和SAM),等我什么时候学会了再单独开一篇文章吧……
字符串Hash
字符串Hash主要是将一个字符串变成64位无符号数字,将每一个字符的ascii码当作该位的值,将一个常数P当作进制来计算。将字符串转换成Hash值是一个很通用的算法,能解决很多题目(除非数据特意卡Hash)。
模板 进制Hash
P3370 字符串哈希
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #define ull unsigned long long const ull P=131 ;ull BHash (string s) ull ans=0 ; for (const auto &c:s)ans=ans*P+c; return ans; } void solve () int n; cin>>n; set<ull>st; string s; while (n--) { cin>>s; st.insert (BHash (s)); } cout<<st.size ()<<endl; }
CF182D Common Divisors
CF182D Common Divisors
通过主串Hash可以直接推出子串的Hash值。对于字符串s,由a和b两个字串拼接形成,即s==a+b。根据Hash函数的定义,可以得到:(这个过程可以类比数字的拆分)
1 Hash (s) == Hash (a)*Pow (P, len (b)) + Hash (b);
因此,求字串b的Hash值的公式:
1 Hash (b) == Hash (s) - Hash (a)*Pow (P, len (b));
这道题是让我们找公因子串有多少个,我们可以枚举两个字符串长度的公因数,看这个长度的字串是否为两个字符串的公因字串,使用进制Hash进行判断。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #include <bits/stdc++.h> #define int long long #define endl '\n' #define ull unsigned long long using namespace std;void solve () void init () signed main () ios::sync_with_stdio (false ); cin.tie (0 ); int t=1 ; init (); while (t--)solve (); cout.flush (); return 0 ; } const int N=1e5 +2 ;ull P[N],h1[N],h2[N]; char s[N],t[N];const int p=131 ;void solve () cin>>(s+1 ); cin>>(t+1 ); int n=strlen (s+1 ); int m=strlen (t+1 ); for (int i=1 ;i<=n;i++)h1[i]=h1[i-1 ]*p+s[i]-'a' ; for (int i=1 ;i<=m;i++)h2[i]=h2[i-1 ]*p+t[i]-'a' ; int ans=0 ; for (int i=1 ;i<=min (n,m);i++) { if (n%i!=0 ||m%i!=0 )continue ; bool fg1=false ,fg2=false ; for (int j=0 ;j+i<=n&&!fg1;j+=i)fg1=h1[i]!=h1[j+i]-h1[j]*P[i]; for (int j=0 ;j+i<=m&&!fg2;j+=i)fg2=h2[i]!=h2[j+i]-h2[j]*P[i]; if (!fg1&&!fg2&&h1[i]==h2[i])ans++; } cout<<ans<<endl; } void init () P[0 ]=1 ; for (int i=1 ;i<N;i++)P[i]=P[i-1 ]*p; }
二分Hash ANT-Antisymmetry
POI2010 ANT-Antisymmetry
首先,符合本题要求的子串一定要是偶数长度。二分寻找以s[x]为中心的回文串,l是以s[x]为中心,找到的最长回文串半径为mid,则这个最长回文串内部有l个回文串。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 const int N=1e7 ;char s[N],t[N];const int PP=131 ;ull P[N],hashs[N],hasht[N]; ull query (int x,int n) ull l=0 ,r=min (x,n-x),mid; while (l<r) { mid=(l+r+1 )>>1 ; if (hashs[x]-hashs[x-mid]*P[mid]==hasht[x+1 ]-hasht[x+1 +mid]*P[mid])l=mid; else r=mid-1 ; } return l; } void solve () int n; cin>>n; P[0 ]=1 ; cin>>(s+1 ); for (int i=1 ;i<=n;i++) { if (s[i]=='0' )t[i]='1' ; else t[i]='0' ; hashs[i]=hashs[i-1 ]*PP+s[i]; P[i]=P[i-1 ]*PP; } for (int i=n;i>0 ;i--)hasht[i]=hasht[i+1 ]*PP+t[i]; ull ans=0 ; for (int i=1 ;i<=n;i++)ans+=query (i,n); cout<<ans<<endl; }
字典树/Trie树
字典树(Trie树)是很多自动机的底子。通过二维数组实现,每一个节点都有最多128条边(如果只涉及小写字母则只需要26条边),每条边代表一个字符。0号节点为根,代表空字符串。沿着Trie树每条边走都可以找到对应的字串。根据需要在每个字符串的最后一位所在的节点打标记。
P8306 【模板】字典树
P8306 字典树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 int cti (char s) if (s>='A' &&s<='Z' )return s-'A' ; else if (s>='a' &&s<='z' )return s-'a' +26 ; else if (s>='0' &&s<='9' )return s-'0' +52 ; return -1 ; } const int N=3e6 +5 ;int idx[N][62 ],cnt[N];int id=1 ;void trieInsert (string s) int p=0 ; for (int i=0 ;i<s.length ();i++) { int c=cti (s[i]); if (!idx[p][c])idx[p][c]=id++; p=idx[p][c]; cnt[p]++; } } int trieget (string s) int p=0 ; for (int i=0 ;i<s.length ();i++) { int c=cti (s[i]); if (!idx[p][c])return 0 ; p=idx[p][c]; } return cnt[p]; } void solve () int n,q; cin>>n>>q; for (int i=0 ;i<id;i++)cnt[i]=0 ; for (int i=0 ;i<id;i++)for (int j=0 ;j<62 ;j++)idx[i][j]=0 ; id=1 ; string s; while (n--) { cin>>s; trieInsert (s); } while (q--) { cin>>s; cout<<trieget (s)<<endl; } }
OpenJ_Bailian Shortest Prefixes
Shortest Prefixes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 int tr[10000 ][26 ];int cnt[100000 ];int idx=1 ;void update (string s) int p=0 ; for (int i=0 ;i<s.length ();i++) { if (!tr[p][s[i]-'a' ])tr[p][s[i]-'a' ]=idx++; cnt[p]++; p=tr[p][s[i]-'a' ]; } cnt[p]++; } int get (string s) int ans=0 ,p=0 ; for (int i=0 ;i<s.length ();i++) { if (cnt[p]==1 )return ans; p=tr[p][s[i]-'a' ]; ans++; } return ans; } void solve () vector<string> in; string s; while (cin>>s) { in.push_back (s); update (s); } for (int i=0 ;i<in.size ();i++) { int len=get (in[i]); cout<<in[i]<<' ' ; for (int j=0 ;j<len;j++)cout<<in[i][j]; cout<<endl; } }
【01Trie树】 最长异或路径
对于多组数字按位问题,我们还可以考虑将数字转化成二进制数字,构建01Trie树,用于解决二进制位运算。
P4551 最长异或路径
根据异或的性质,两个数的路径异或可以拆成两个数分别到根节点的异或值的异或。我们可以先把所有到根节点的异或值存起来,然后在01Trie树上找与这个值异或的最大值,即每个进制位尽可能选择相反方向,这样答案才会最大。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 const int N=1e5 +2 ;int tr[N<<4 ][2 ];int cnt[N<<4 ];int idx=1 ;const string pat = "0000000000000000000000000000000" ;string itos (int val) string ans (pat) ; int i=pat.length ()-1 ; while (val) { if (val&1 )ans[i]='1' ; val>>=1 ; i--; } return ans; } void update (int val) string s=itos (val); int p=0 ; for (int i=0 ;i<s.length ();i++) { if (!tr[p][s[i]-'0' ])tr[p][s[i]-'0' ]=idx++; p=tr[p][s[i]-'0' ]; } cnt[p]=1 ; } seti h[N]; seti dis; mppi wei; void dfs (int i,int val) dis.insert (val); for (const auto &x:h[i]) { dfs (x,val^wei[{i,x}]); } } void solve () int n; cin>>n; int u,v,w; for (int i=1 ;i<n;i++) { cin>>u>>v>>w; if (u>v)swap (u,v); wei[{u,v}]=w; h[u].insert (v); } dfs (1 ,0 ); for (const auto &x:dis)update (x); int ans=0 ; for (const auto &x:dis) { string s=itos (x); int sum=0 ,p=0 ,n=30 ; for (const auto &c:s) { if (tr[p][(c-'0' )^1 ]) { sum|=(1ull <<n); p=tr[p][(c-'0' )^1 ]; } else p=tr[p][c-'0' ]; n--; } ans=max (ans,sum); } cout<<ans<<endl; }
KMP —— 单匹配字符串算法
KMP算法思路
基于匹配串t,我们要将fail数组的初始化,fail[j]表示为以s[j]结尾的前缀中最长公共前后缀的长度 。那么fail[j-1]就以s[j-1]结尾的最长公共前后缀的长度。我们计算fail[j]时,如果s[j] == s[fail[j-1]],也就是新加进来的字符和j-1处最长公共前后缀尾部的字符相同,说明可以构成fail[j-1]+1长度的最大公共前后缀。
如果s[j] != s[fail[j-1]],那么我们就去找fail[j-1]长度的字串的最长公共前后缀 。直到找到了或者j==0也没有找到。
1 2 3 4 5 6 7 8 9 fail[0 ]=0 ; for (int i=1 ;i<t.length ();i++){ int j=fail[i-1 ]; while (j&&t[i]!=t[j])j=fail[j-1 ]; if (t[i]==t[j])j++; fail[i]=j; }
接下来就是在s中寻找t,i指针不进行回退操作。如果s[i]==t[j]那么i与j均前进。
反之如果失配,那么j就回退到fail[j-1]处,即跳过当前(以j结尾的)最长公共前后缀,直接进行匹配最长公共前后缀的下一个字符。
如果j==t.length(),则说明在s中找到了t。如果需要进一步匹配,则还是令j=fail[j-1],再跳过最长公共前后缀重新寻找。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int i=0 ,j=0 ;int n=s.length (), m=t.length ();while (i<n){ if (s[i]==t[j]) { i++,j++; if (j==m) { cout<<i-m+1 <<endl; j=fail[j-1 ]; } continue ; } if (!j)i++; else j=fail[j-1 ]; }
P3375 【模板】KMP
P3375 KMP
将上述代码整合就行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 const int N=1e6 +5 ;int fail[N];void solve () string s,t; cin>>s>>t; int n=s.length (),m=t.length (); for (int i=1 ;i<m;i++) { int j=fail[i-1 ]; while (j&&t[i]!=t[j])j=fail[j-1 ]; if (t[i]==t[j])j++; fail[i]=j; } int i=0 ,j=0 ; while (i<n) { if (s[i]==t[j]) { i++,j++; if (j==m) { cout<<i-m+1 <<endl; j=fail[j-1 ]; } continue ; } if (!j)i++; else j=fail[j-1 ]; } for (int i=0 ;i<m;i++)cout<<fail[i]<<' ' ; cout<<endl; }
【POJ2752】Seek the Name, Seek the Fame
POJ2752 Seek the Name, Seek the Fame
这题要求既是后缀又是前缀字串的长度。fail[n-1]为整个字符串的最长公共前后缀,那么对于长度为fail[n-1]的前缀,它的最长公共前后缀也是原字符串的后缀。因此,沿着j=fail[j-1]这个过程记录值就可以。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 const int N=1e6 +5 ;int fail[N];void solve () string s; while (cin>>s) { fail[0 ]=0 ; int n=s.length (); for (int i=1 ;i<n;i++) { int j=fail[i-1 ]; while (j&&s[i]!=s[j])j=fail[j-1 ]; if (s[i]==s[j])j++; fail[i]=j; } seti ans; int j=n; while (j) { ans.insert (j); j=fail[j-1 ]; } for (const auto &x:ans)cout<<x<<' ' ; cout<<endl; } }
CF1137B Camp Schedule
CF1137B Camp Schedule
我们可以模拟KMP匹配的过程,构造出的s尽可能匹配t,且充分利用最长公共前后缀节省开销。对于实在无法匹配的部分(某个数字用完了)我们只好做失配处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 const int N=1e6 +5 ;int fail[N];void solve () string s,t; cin>>s>>t; for (int i=1 ;i<t.length ();i++) { int j=fail[i-1 ]; while (j&&t[j]!=t[i])j=fail[j-1 ]; if (t[i]==t[j])j++; fail[i]=j; } int cnt0=0 ,cnt1=0 ; for (const auto &c:s) { if (c=='1' )cnt1++; else if (c=='0' )cnt0++; } int i=0 ,j=0 ; while (i<s.length ()) { if (t[j]=='1' ) { if (cnt1) { cnt1--; cout<<'1' ; i++,j++; if (j==t.length ())j=fail[j-1 ]; } else { if (!j) { cout<<'0' ; i++; cnt0--; } else j=fail[j-1 ]; } } else if (t[j]=='0' ) { if (cnt0) { cnt0--; cout<<'0' ; i++,j++; if (j==t.length ())j=fail[j-1 ]; } else { if (!j) { cout<<'1' ; i++; cnt1--; } else j=fail[j-1 ]; } } } cout<<endl; }
Manacher 最长回文
这个算法可以高效的处理最长回文。首先将字符串使用特殊的符号分隔,使长度变为奇数,之后利用动态规划的思想,计算出以每个字符为中心时最大的回文半径。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 const int N=1e6 +5 ;char t[N];char s[N];int d[N];int Manacher (char *a,int n) int k=0 ; s[k++]='$' ; for (int i=0 ;i<n;i++) { s[k++]='#' ; s[k++]=a[i]; } s[k++]='#' ; n=k; a=s; d[1 ]=1 ; for (int i=2 ,l=1 ,r=1 ;i<=n;i++) { if (i<=r)d[i]=min (r-i+1 ,d[r-i+l]); while (s[i-d[i]]==s[i+d[i]])d[i]++; if (i+d[i]-1 >=r) { l=i-d[i]+1 ; r=i+d[i]-1 ; } } int ans=0 ; for (int i=1 ;i<=n;i++)ans=max (ans,d[i]); return ans-1 ; } void solve () cin>>t; cout<<Manacher (t,strlen (t))<<endl; }
AC自动机 —— 多匹配字符串算法
AC自动机是处理多匹配字符串问题的。基于Trie树,通过建立回跳边和转移边,优化匹配指针的回跳。
AC自动机构建流程
首先利用所有模式串建立Trie树。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 const int N=2e5 +2 ;int tr[N<<4 ][26 ];int idx=1 ;int tag[N<<4 ];void trie (string s,int i) int p=0 ; for (const auto &c:s) { if (!tr[p][c-'a' ])tr[p][c-'a' ]=idx++; p=tr[p][c-'a' ]; } tag[p]=1 ; h[i]=p; }
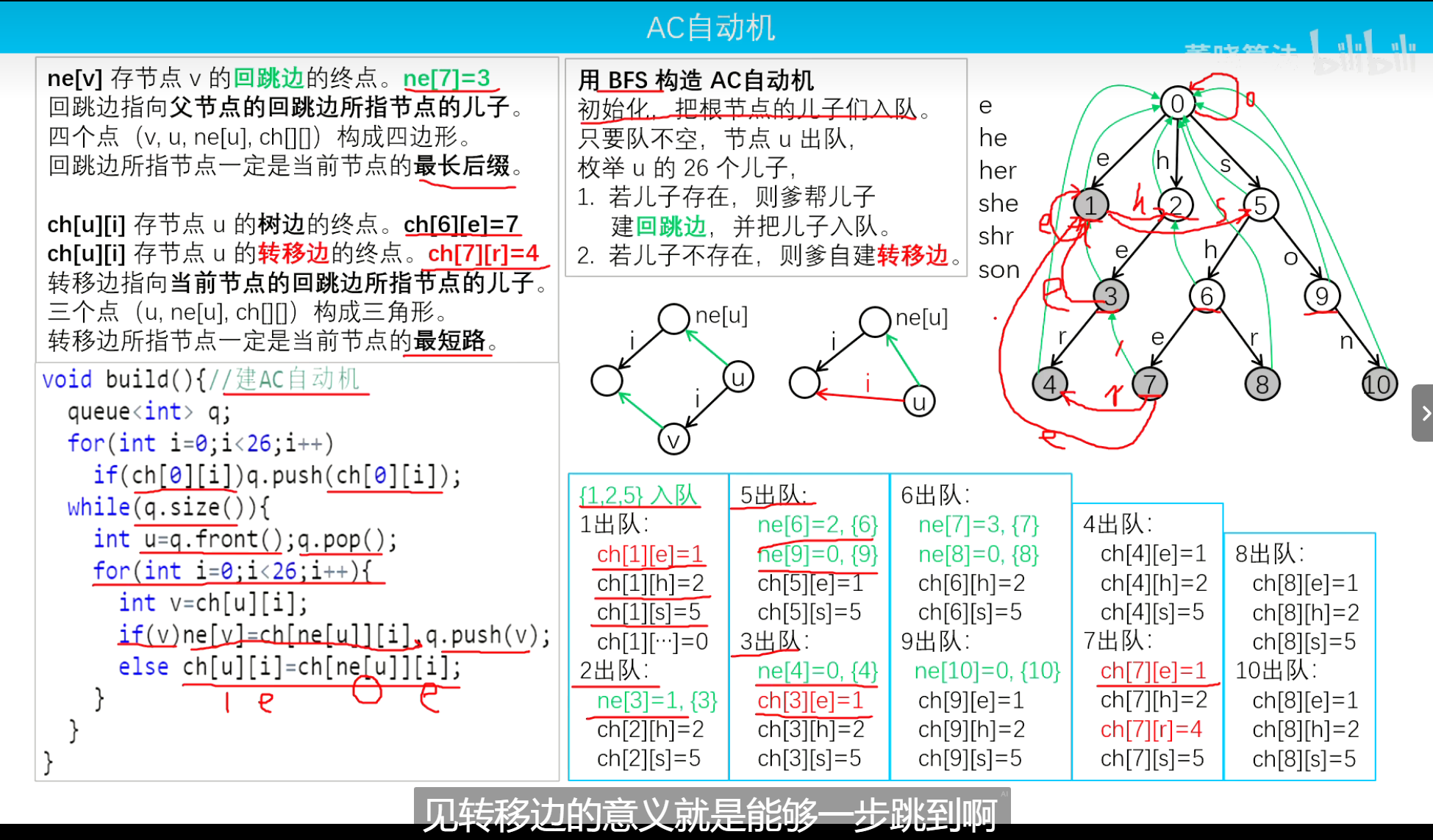
之后利用BFS为每一个节点 构建回跳边和转移边。
首先将0号节点(根节点)的所有存在的子节点压入队列中。
遍历队列,每次取出队列头的节点。遍历这个节点的所有边指向的子节点。
如果这个子节点存在,则帮这个子节点建立回跳边 ,用fail数组存节点的回跳边;反之如果这个边不存在,则建立自己的转移边 。
某个节点的回跳边是父节点的回跳边所指节点的儿子 ;转移边是当前节点的回跳边所指节点的儿子 。
回跳边所指节点一定是当前节点的最长后缀。
alt text
(图源:bilibili 董晓算法 AC自动机 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void buildAC () queue<int >q; for (int v=0 ;v<26 ;v++)if (tr[0 ][v])q.push (tr[0 ][v]); while (!q.empty ()) { int u=q.front (); q.pop (); for (int i=0 ;i<26 ;i++) { int v=tr[u][i]; if (v) { fail[v]=tr[fail[u]][i]; q.push (v); } else tr[u][i]=tr[fail[u]][i]; } } }
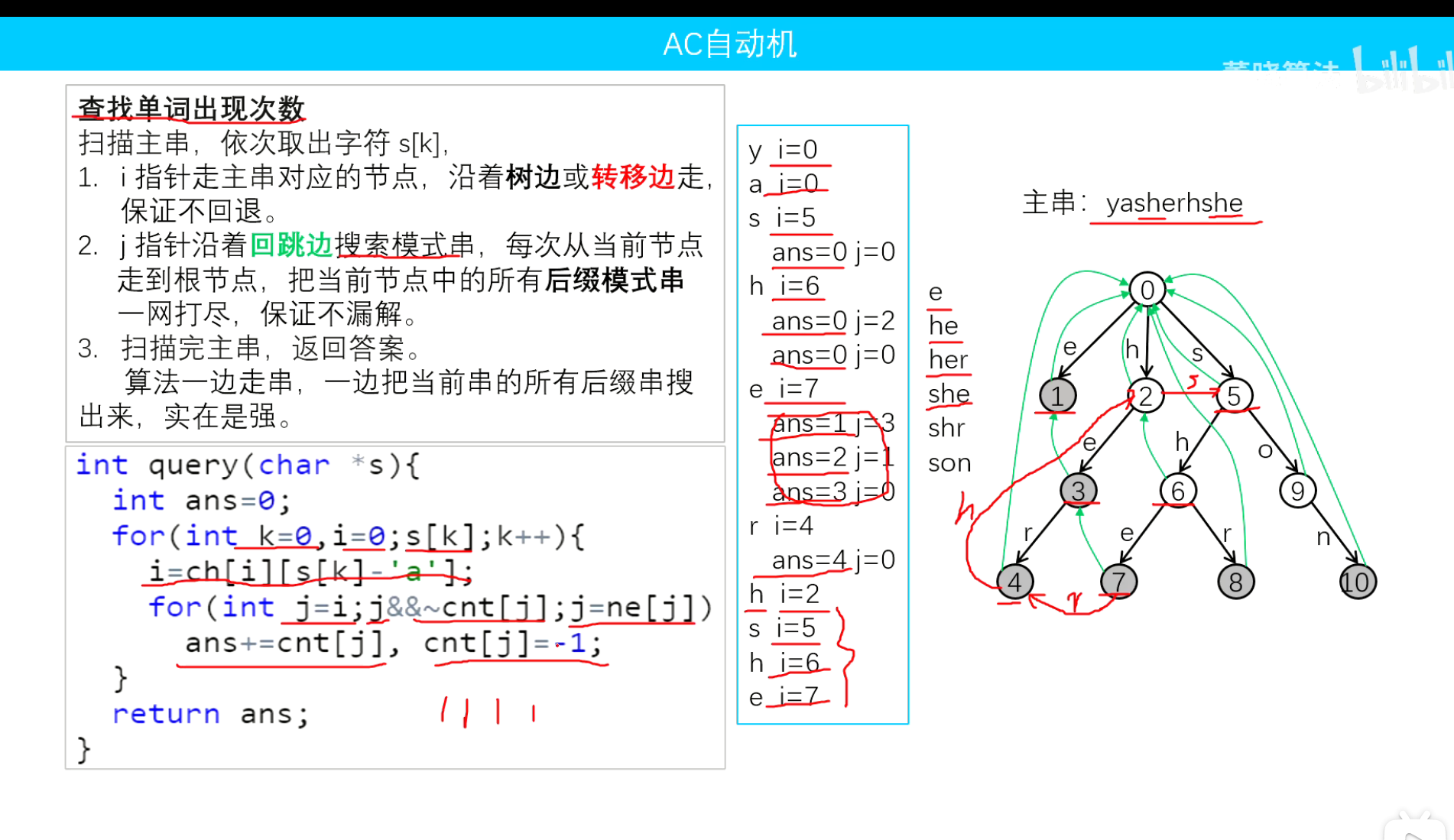
查找流程:
首先定义i指针和j指针,i指针利用匹配串s,在Trie树上不断前进(由于我们对叶子节点建立了合适的转移边,所以不会产生数组溢出)j指针沿着回跳边去搜索模式字符串,这个过程如果某一个节点有标记,说明匹配到了模式字符串,进行计次。
alt text
1 2 3 4 5 6 7 8 9 void queryAC (string s) int i=0 ; for (const auto &c:s) { i=tr[i][c-'a' ]; for (int j=i;j;j=fail[j])if (tag[j])cnt[j]++; } }
更详细说明可以看一下:OI Wiki AC自动机
P5357 AC自动机(二次加强版)
P5357 AC自动机(二次加强版)
AC自动机(简单版)可以通过刚才的板子通过。然而在数据量比较大的情况下,j指针不断的沿着回跳边回调会产生很大的时间浪费。因此我们需要优化这一过程。
因为每次j指针都是将答案从深度大的节点传递到深度小的节点,所以我们可以当i指针全部跑完之后最后去处理这个过程。每次i指针跑到某一节点,我们就对这个节点的cnt++,不管是不是模式串(因为有可能它的某个后缀是模式串)。
在建立AC自动机的时候,我们可以记录每一个节点的入度,显然入度为0的节点是最深层的节点。而u的唯一出度指向的节点就是fail[u],利用拓扑排序,可以将cnt数组记录的值从下到上传递上去。
完整代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 const int N=2e5 +2 ;int tr[N<<4 ][26 ];int idx=1 ;int tag[N<<4 ];int cnt[N<<4 ];int fail[N<<4 ];int h[N<<4 ];int in[N<<4 ];void trie (string s,int i) int p=0 ; for (const auto &c:s) { if (!tr[p][c-'a' ])tr[p][c-'a' ]=idx++; p=tr[p][c-'a' ]; } tag[p]=1 ; h[i]=p; } void buildAC () queue<int >q; for (int v=0 ;v<26 ;v++)if (tr[0 ][v])q.push (tr[0 ][v]); while (!q.empty ()) { int u=q.front (); q.pop (); for (int i=0 ;i<26 ;i++) { int v=tr[u][i]; if (v) { fail[v]=tr[fail[u]][i]; q.push (v); in[fail[v]]++; } else tr[u][i]=tr[fail[u]][i]; } } } void queryAC (string s) int i=0 ; for (const auto &c:s) { i=tr[i][c-'a' ]; cnt[i]++; } queue<int >q; for (int i=1 ;i<idx;i++)if (!in[i])q.push (i); while (!q.empty ()) { int u=q.front (); q.pop (); int v=fail[u]; in[v]--; cnt[v]+=cnt[u]; if (!in[v])q.push (v); } } void solve () int n; cin>>n; string s; for (int i=1 ;i<=n;i++) { cin>>s; trie (s,i); } cin>>s; buildAC (); queryAC (s); for (int i=1 ;i<=n;i++)cout<<cnt[h[i]]<<endl; }
KMP和AC自动机的应用
HDU7455 在A里面找有C的B(KMP+AC自动机)
HDU7455在A里面找有C的B
KMP+AC自动机模板的综合题。首先利用KMP判断每一个B1中是否有C,有的话将B插入Trie树中。之后再用AC自动机统计A中出现B的次数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 #define VLSMB_VS #include <bits/stdc++.h> #define int long long #define endl '\n' #define ull unsigned long long using namespace std;void solve () signed main () ios::sync_with_stdio (false ); cin.tie (0 ); int t=1 ; cin>>t; while (t--)solve (); cout.flush (); return 0 ; } const int N=5e6 ;int tr[N][26 ];int tag[N];int h[N];int cnt[N];int fail[N];int in[N];int idx=1 ;void update (string s,int i) int p=0 ; for (const auto &c:s) { if (!tr[p][c-'a' ])tr[p][c-'a' ]=idx++; p=tr[p][c-'a' ]; } tag[p]++; h[i]=p; } void buildAC () queue<int >q; for (int i=0 ;i<26 ;i++)if (tr[0 ][i])q.push (tr[0 ][i]); while (!q.empty ()) { int u=q.front (); q.pop (); for (int j=0 ;j<26 ;j++) { int v=tr[u][j]; if (v) { fail[v]=tr[fail[u]][j]; q.push (v); in[fail[v]]++; } else tr[u][j]=tr[fail[u]][j]; } } } void queryAC (string s) int i=0 ; for (const auto &c:s) { i=tr[i][c-'a' ]; cnt[i]++; } queue<int >q; for (int i=1 ;i<idx;i++)if (!in[i])q.push (i); while (!q.empty ()) { int u=q.front (); q.pop (); int v=fail[u]; in[v]--; cnt[v]+=cnt[u]; if (!in[v])q.push (v); } } int kmp[N];bool kmpexist (string s,string t) int n=s.length (),m=t.length (); int i=0 ,j=0 ; while (i<n) { if (s[i]==t[j]) { i++,j++; if (j==m)return true ; continue ; } if (!j)i++; else j=kmp[j-1 ]; } return j==m; } void solve () for (int i=0 ;i<idx;i++) { tag[i]=0 ; cnt[i]=0 ; fail[i]=0 ; in[i]=0 ; for (int j=0 ;j<26 ;j++)tr[i][j]=0 ; } for (int i=0 ;i<N;i++)h[i]=0 ,kmp[i]=0 ; idx=1 ; int n; cin>>n; string A,C,B,B1; cin>>A>>C; kmp[0 ]=0 ; for (int i=1 ;i<C.length ();i++) { int j=kmp[i-1 ]; while (j&&C[j]!=C[i])j=kmp[j-1 ]; if (C[j]==C[i])j++; kmp[i]=j; } for (int i=1 ;i<=n;i++) { cin>>B>>B1; if (kmpexist (B1,C)) update (B,i); } buildAC (); queryAC (A); for (int i=1 ;i<=n;i++)if (cnt[h[i]]&&h[i])cout<<i<<' ' ; cout<<endl; }
USACO15FEB Censoring 1
USACO February 2015 Contest Censoring 1
这题要利用KMP的匹配性质。定义一个pair<char,int> ans[N]数组,用来存储临时答案。char部分当然就是要输出的答案了,而int部分是记录i指针扫到这个字符的时候j的值是多少。
当遇见与模式字符串匹配时,我们要将之前放入ans数组的模式串放弃掉(使用k-=m这个操作),并且将j指针恢复到操作后ans剩余的最后一个字符所存的j的值 ,而不是用fail指针回退。
举个可能不恰当的例子,这个过程就像是线程保护和恢复,恢复之前保存的j指针让这个匹配过程的函数“不知道”我们删除了部分字符,还是正常进行匹配操作。
(就像是Inline Hook的时候保存线程标志寄存器的值,执行完自己的汇编码之后又恢复标志寄存器,再跳回原线程的代码,原线程在此过程中根本没察觉到多执行了一部分汇编码。)
说了那么多废话,其实ans就是一个栈。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 #define VLSMB_VS #include <bits/stdc++.h> #define int long long #define pii pair<int,int> #define endl '\n' using namespace std;void solve () signed main () ios::sync_with_stdio (false ); cin.tie (0 ); int t=1 ; while (t--)solve (); cout.flush (); return 0 ; } const int N=1e7 ;pair<char ,int > ans[N]; int fail[N];void solve () string s,t; cin>>s>>t; int n=s.length (),m=t.length (); fail[0 ]=0 ; for (int i=1 ;i<m;i++) { int j=fail[i-1 ]; while (j&&t[i]!=t[j])j=fail[j-1 ]; if (t[i]==t[j])j++; fail[i]=j; } int i=0 ,j=0 ,k=0 ; while (i<n) { if (s[i]==t[j]) { ans[k].first=s[i]; j++; ans[k].second=j; k++; i++; if (j==m) { k-=m; if (k)j=ans[k-1 ].second; else j=0 ; } continue ; } if (!j) { ans[k].first=s[i]; ans[k].second=j; k++; i++; } else j=fail[j-1 ]; } for (int i=0 ;i<k;i++)cout<<ans[i].first; cout<<endl; }
USACO15FEB Censoring G
USACO15FEB Censoring G
属于是上一道题的加强版。只不过变成了多个字符串删除。处理方式一样,只不过换一个AC自动机而已。
在AC自动机里状态指针是i,别记录错了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 #define VLSMB_VS #include <bits/stdc++.h> #define int long long #define pii pair<int,int> #define endl '\n' using namespace std;void solve () signed main () ios::sync_with_stdio (false ); cin.tie (0 ); int t=1 ; while (t--)solve (); cout.flush (); return 0 ; } const int N=2e6 ;int tr[N][26 ];int idx=1 ;int tag[N];int fail[N];pair<char ,int > ans[N]; void trie (string s) int p=0 ; for (const auto &c:s) { if (!tr[p][c-'a' ])tr[p][c-'a' ]=idx++; p=tr[p][c-'a' ]; } tag[p]=s.length (); } void buildAC () queue<int >q; for (int v=0 ;v<26 ;v++)if (tr[0 ][v])q.push (tr[0 ][v]); while (!q.empty ()) { int u=q.front (); q.pop (); for (int i=0 ;i<26 ;i++) { int v=tr[u][i]; if (v) { fail[v]=tr[fail[u]][i]; q.push (v); } else tr[u][i]=tr[fail[u]][i]; } } } void queryAC (string s,int &k) int i=0 ; for (const auto &c:s) { i=tr[i][c-'a' ]; ans[k].first=c; ans[k].second=i; k++; if (tag[i]) { k-=tag[i]; if (k)i=ans[k-1 ].second; else i=0 ; } } } void solve () int n; string s,t; cin>>s>>n; for (int i=1 ;i<=n;i++) { cin>>t; trie (t); } int k=0 ; buildAC (); queryAC (s,k); for (int i=0 ;i<k;i++)cout<<ans[i].first; cout<<endl; }